With the releases of iOS 14 and tvOS 14 last week, Apple is offering widespread support for low-latency live streaming on more than a billion devices. In this article, we wanted to review the rationale behind developing LL-HLS, explain the improvement over HLS and compare LL-HLS with the competing implementation of low latency in DASH. The article concludes on where LL-HLS is likely to take video delivery and how Broadpeak can help.
What is LL-HLS?
Media streaming over the internet relies on two key protocols: HLS promoted by Apple at the IETF, and DASH from MPEG. These protocols enable video delivery to a wide range of devices, including those connected wirelessly thanks to the use of reliable transmission leveraging HTTP and multiple different bit rates to adapt to network condition changes (ABR streaming).
However, over the last few years, these ABR protocols have fallen short of enabling low-latency playback. Indeed, typical latency in the delivery of the video (from packaging to playback) can be in the range of 6 to 30 seconds depending on players and configuration, even in ideal network conditions. The latency problem has become a hurdle, preventing further ABR deployments such as replacing broadcast or traditional IPTV for latency sensitive content like sports, news, and other live events.
Latency is cumulative, hence it is added along the whole delivery path from transcoding to the client through the CDN (packaging/origin and caching). Yet, as of today, most of the latency comes from the client: Due to the operation of the protocol (HLS or DASH), and the request/response cycles necessary to obtain the media segments, clients have to maintain a large enough buffer to ensure smooth playback. As an example, an Apple HLS client will start playback once it has buffered at least two segments, resulting in observed latency ranging from 5 to 18 seconds depending on segment durations (2 to 6 seconds).
To address these issues, both standards have proposed low-latency extensions altering the delivery to the client so that the client can reduce the size of its buffers its buffer sizes:
- On one side, DASH has built a proposal relying on CMAF combined with HTTP/1.1 chunked transfer encoding to limit the latency induced by the packaging step, with minimal changes on the player side.
- On the other side, Apple has presented the low-latency extensions for HLS at WWDC mid-2019, and they have become generally supported on iOS, tvOS, and macOS players with the recent release of iOS14. These extensions are particularly important as HLS (hence LL-HLS) playback is the only way to support a complete video experience on iOS/tvOS, including with DRMs.
With LL-HLS, Apple has made the four following significant additions to the existing HLS.
1.Reducing delays related to the packaging
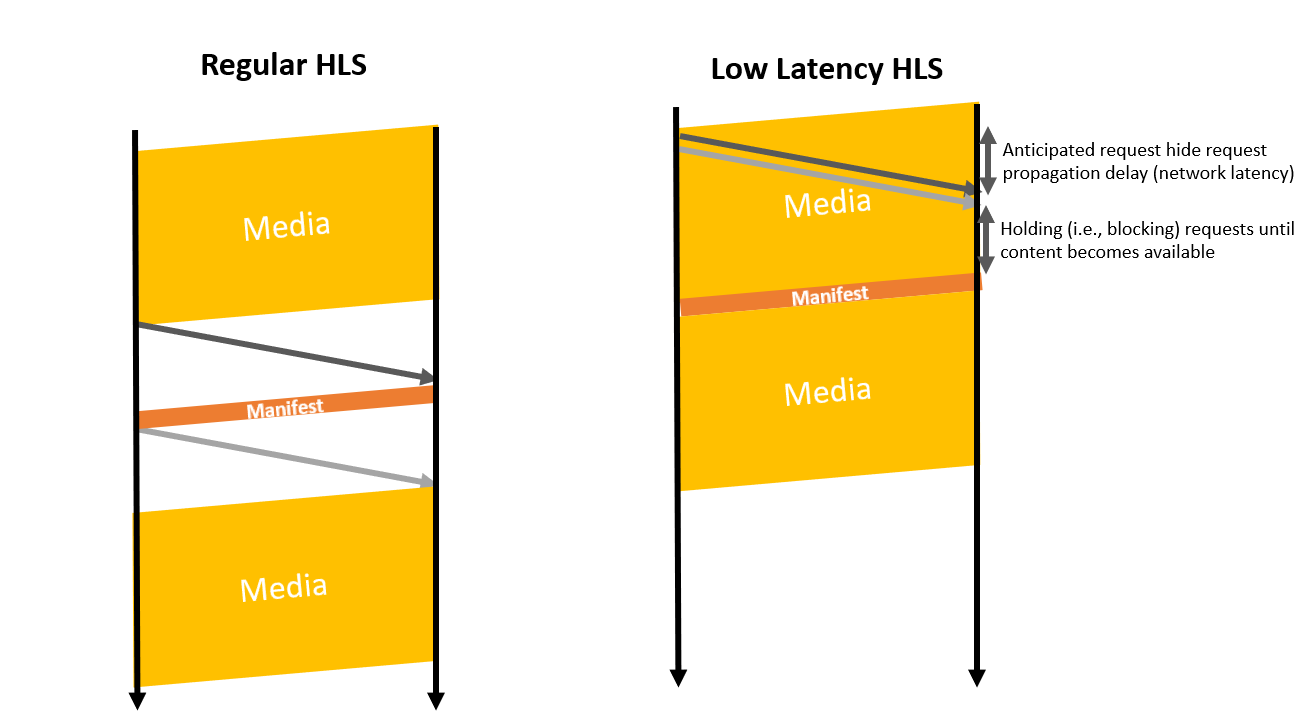
In non-low latency packaging, a complete segment (e.g., 2-6 seconds’ worth of video) is published, in a single shot, only once it is complete (i.e., at the end of the 2-6 second period). As a consequence, the delivery of the beginning of that segment can only start once the end of the segment has been encoded and packaged. In LL-HLS, to avoid that induced latency, information about CMAF chunks (i.e., parts in HLS terminology, 500ms worth of video) is published to the manifest before the segment is complete. Similarly to DASH Low Latency, this allows the delivery to happen before the segment is fully packaged, saving up to 1.5 to 5.5 seconds of latency depending on the segment duration.

2. Improving timely manifest delivery
In live HLS, the manifest is refreshed every 2-6 seconds in order to discover new media segments. If the manifest is obtained just before it is updated, the player has to wait and retry, resulting in unnecessary latency. In LL-HLS, the client can indicate to the server that it wants a version of the manifest containing at least a given segment number using the query arguments _HLS_msn. The server will hold the request until it can provide the client with the requested manifest, thus ensuring a more timely manifest delivery, saving some precious tenths of a second in discovering the availability of new parts and segments.
In addition, live HLS had issues with manifest sizes in some context (e.g., when using two-hours DVR as recommended for Apple TVs): the delivery of a large manifest can consume a significant portion of the bandwidth despite minor changes to the manifest content. The issue, present in HLS, is becoming more prevalent in LL-HLS as the manifest is both larger with the additional description of parts and obtained every 500 ms rather than every 2 to 6 seconds. To address this issue, Apple has introduced EXT-X-SKIP tags that can be used to build a delta playlist that only describes recent changes to the manifest (e.g., the last 12 seconds). This approach departs from the SegmentTemplate approach in DASH, and shares similarity with the upcoming manifest patches in DASH v4.
3. Reducing delays related to request propagation
When chasing for low latency, buffers in the players are set to very low levels, implying that any hiccup in delivery will have an impact on the user experience. One of these hiccups can be the delay, related to roundtrip time, between the time a request is sent and first bytes of the response are received. On busy Wi-Fi or cellular networks, these roundtrip times can increase to hundreds of milliseconds when the network is loaded with traffic, thus resulting in significant delays. This delay has an especially strong impact on LL-HLS as it issues requests for manifests and media every 500ms rather than 2 to 6 seconds in HLS or DASH.
To hide this delay, the approach adopted in LL-HLS is to send the request in anticipation, rather than sending the request once the segment (or part) is known to be available. As the requested segment or manifest may not be available or updated yet when the server receives the request, the server will hold that request until it becomes available, and will thus be able to send data as soon as they become available.
This specific holding (i.e., blocking) server behavior is precisely specified in the HLS RFC that details how the server should behave regarding requests. While the issue is present in DASH too, DASH does not mandate a specific server behavior, thus preventing the client from making assumptions. Indeed, the DASH client cannot anticipate requests, as the server may reply 404 Not Found, and the server may not block as it does not know how the client will handle that blocking (e.g., the DASH client may include blocking time in its bandwidth estimation, resulting in bandwidth underestimation). Thus, HLS-LL, through its precise specification of client and server behavior, allow optimizing the request processing on both sides.
4. Requiring an update to the underlying HTTP protocol
Again, to target low latency, buffers in the players are set to very low levels, requiring efficient and reliable delivery. The regular HLS relied on HTTP for content delivery, and supported any version of HTTP, including the dated HTTP/1.1 from 1999.
LL-HLS departs from this unrestrictive approach. To allow efficient and robust delivery, LL-HLS mandates HTTP/2 and recommends a number of modern TCP settings (e.g., TCP RACK, ECN, …). HTTP/2 allows all request/responses to go over a single TCP connection, avoiding self-congestion between two concurrent TCP connections transporting audio and video separately. This is especially important as low buffer levels are used in the player for low-latency playback. Apple’s implementation of the LL-HLS player tests that these settings are satisfied before engaging into low-latency playback, and we’ve observed that it quickly falls back to regular playback (plain HLS) as a safety measure if any condition is not satisfied.
In addition, HTTP/2 mandates itself due to the prevalent use of blocking requests resulting from additions (2) and (3), which could hit limits regarding connection pool sizes in HTTP/1.1 in popular browsers. This issue is described in more detail in RFC6202 (Sec 5.1). Indeed, most browsers limit the number of concurrent requests to a single server to six, which could easily be hit with multiple forms of media (i.e., audio, video, subtitles), where each media could have up to four in-flight requests (one for current manifest, one for future manifest, one for current media and one for future media). This would prevent proper delivery of the content.
These two points explain why HTTP/2 in still mandatory in the current revision of the standard, despite the requirement for HTTP/2 Push having been dropped during LL-HLS beta phase.
These changes, addressing both packaging, transport and client-server interaction provide a comprehensive approach to offering low latency, addressing numerous issues that contribute to the latency. The fact that client-server interactions are fully specified allows efficient and reliable implementation.
Differences and convergence between LL-HLS and DASH-LL
Despite shared goals (i.e., low-latency adaptive streaming) and shared underlying technologies (use of HTTP), LL-HLS and DASH-LL differ on several points.
First, LL-HLS and DASH-LL differ in their use of HTTP. LL-HLS explicitly requires HTTP2 but does not require, in its default variant, progressive transmission (as in CTE for DASH). As a consequence, LL-HLS somehow lowers requirements on caching servers. Indeed, all modern caching servers already support HTTP/2 but may not support the exact transmission behavior required for DASH LL.
Second, LL-HLS departs from clock-based synchronization. Indeed, clock-based synchronization in DASH is hard to get right between clock drift, ambiguity in interpretation of the standard, out-of-sync servers and input discontinuities. By using an explicit synchronization mechanism through blocking requests (i.e., the server hold the request until it can serve the response, thus forcing synchronization), the player can be both simpler and more reliable.
Third, both DASH-LL and LL-HLS rely on chunked CMAF media. However, while DASH-LL signals only segments (i.e., group of multiple CMAF chunks) in the manifest, and issues requests for full segments only, LL-HLS makes the player aware of CMAF chunks by signaling CMAF chunks in the manifest and having the player explicitly request them.
Despite increasing the number of requests for serving the same content, this has two advantages:
- The player has more information on the delivery of chunks (size and time to download), which can be useful for bandwidth estimation, a notable difficulty in DASH-LL.
- Errors in the HTTP protocol can be mapped to a specific chunk, allowing the player to implement retry and recover properly. Indeed, HTTP/1.1 CTE is known to be relatively poor at handling errors once some content has been transmitted, with inconsistent behavior across different browsers or environments.
These differences result in different media chunks or segments addressing between DASH-LL and LL-HLS (i.e., URLs of objects requested by the player differ). This was an early concern for the initial LL-HLS proposition, as different URLs would have hindered efforts to store a single copy of the media (both in caches and origins of CDNs so as to increase cache efficiency). This issue has been addressed in a later revision of LL-HLS by introducing a variant relying on byte ranges that issues a single request for preloading a segment as it gets produced rather than requesting chunks one by one. With this addition, requests by LL-HLS players and DASH-LL players can be identical, thus allowing CDN caches to share content between LL-HLS and DASH-LL. Despite the single media request, this variant is still advantageous over DASH as the player gets information about chunks thanks to the exhaustive manifest, and HTTP/2 error handling is more precisely specified.
Overall, this is a strength compared with the DASH LL approach that uses HTTP CTE exclusively and has not planned any mechanism for detecting abnormal request termination. Yet, this implies an increased number of requests for manifest (up to one per part), which can significantly increase the load on the CDN in number of requests, and the load of all manifest processing entities such as SSAI (e.g., Broadpeak’s BkYou), thus requiring an increased number of manifest manipulation servers.
This evolution shows that despite being developed in parallel with independent low-latency extensions for HLS and DASH, the ecosystems keep converging with identical container formats, thus allowing for more efficient caching at CDNs. HLS and DASH protocols and manifest formats may still coexist for years, each having their merit. Yet, costs related to duplicated caching and duplicated delivery are going down with container and media format unification. We see this convergence going forward with a unification of DRMs toward a single encryption choice (e.g., Common Encryption CBCS or Sample AES in HLS specification), in order to fully benefit from the promises of CMAF.
What does it mean for the Broadpeak CDN and Origin Server?
Broadpeak’s systems are ready for LL-HLS.
Early support for LL-HLS has been implemented in the BkS350 origin packager. When fed with an encoder having a low-latency profile, the BkS350 packages to CMAF and delivers LL-HLS playlists to clients, allowing for an optimal low-latency experience on iOS, tvOS or any third-party player with LL-HLS.
The Broadpeak BkS350 origin packager supports shared DASH/HLS unified segment naming to optimize storage and delivery. In addition, it is able to provide CBCS encryption for both DASH and HLS, thus supporting unified containers and media for improved caching.
The Broadpeak CDN servers (BkS400) support all required protocol features (HTTP/2) and, with the latest version, the recommended settings for LL-HLS (i.e., TCP RACK, ECN) are also supported. This enables efficient delivery for an optimal user experience.
We tested our full system (BKS350 and BkS400) with Apple’s native player (AVPlayer) on iOS/tvOS, and we also tested with our partner THEOplayer, the first third-party player available for LL-HLS. As the natural evolution of HLS published at the IETF, support for LL-HLS will be coming soon in additional players.
Conclusion
With close to a billion active iOS devices, we believe LL-HLS is here to stay. Apple’s careful approach to reduce latency while minimizing the impact on the video ecosystem, combined with the integrated system view (client and server specification) is very powerful.
As live sports return to our screens and LL-HLS live services become available, this approach will without a doubt bring low-latency experiences to large audiences.
Here at Broadpeak we have been working on LL HLS since the early drafts of the specification were published. In conversations with Apple, we implemented the various iterations all the way to the recent release because we saw the benefits of large-scale low-latency solutions, and improving the consumers’ experience continues to drive our innovation.
For a demo of our latest LL-HLS implementation (on any device) :
Visit https://broadpeak.tv/ll-hls/

